

Costs and performance lessons after using BigQuery with terabytes of data
Originally published on medium
I’ve used BigQuery every day with small and big datasets querying tables, views, and materialized views. During this time I’ve learned some things, I would have liked to know since the beginning. The goal of this article is to give you some tips and recommendations for optimizing your costs and performance.
Basic concepts
BigQuery: Serverless, highly scalable, and cost-effective multi-cloud data warehouse designed for business agility [Google Cloud doc].


BigQuery logo
GCP Project: Google Cloud projects form the basis for creating, enabling, and using all Google Cloud services including managing APIs, enabling billing, adding and removing collaborators, and managing permissions for Google Cloud resources [Google Cloud doc]. Each project could have more than one BigQuery Dataset.

GCP Project
Dataset: It’s similar to the Databases or Schema concepts in other RDBMS. There are located tables, views, and materialized views.
BigQuery’s Datasets
Slot: It’s a virtual CPU used by BigQuery to execute SQL queries. BigQuery automatically calculates how many slots are required by each query, depending on query size and complexity [Google Cloud doc]. This is the principal indicator if you are in flat-rate pricing because you make a slot commitment (minimum 500 slots).
Slot/ms: It’s the total amount of slots per millisecond used by a query. That’s the total number of slots consumed by the query over its entire execution time [Taking a practical approach to BigQuery slot usage analysis]. Notice that a query uses a different quantity of slots during all execution, for example, the number of slots when start making a join is higher than making a filter and also is the duration time.
Numer of byte processed: It’s the total bytes read when you run a query. This is the principal cost if you are in on-demand pricing.


Getaway of “Select * “
Partition: A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data [BigQuery partitioned table].

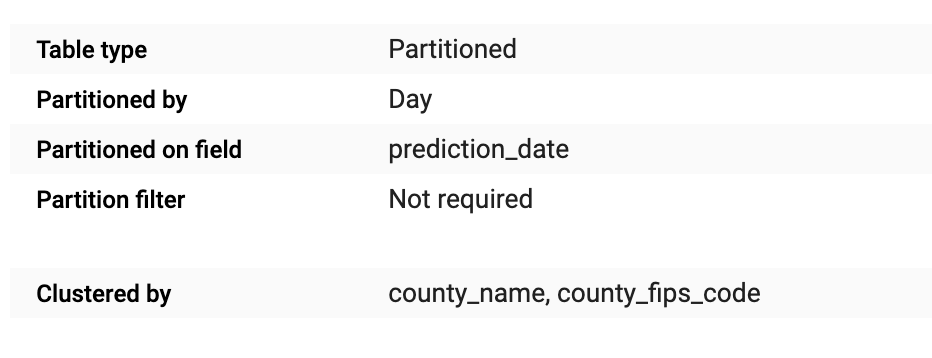
A partitioned and clustered table
Clustering: A clustered table data is automatically organized based on the contents of one or more columns in the table’s schema [BigQuery clustered table].
Resuming this two important concepts, I’ve made a simple image to understand visually how a table get organized.


Cost recommendations
There is not a magic recipe, however, It’s important to understand the BigQuery’s cost structure and then what exactly I’m spending on it.
Cost Structure
Storage [pricing]
Active: A monthly charge for data stored in tables or in partitions that have been modified in the last 90 days. $0.020 per GB
- Long-term: A lower monthly charge for data stored in tables or in partitions that have not been modified in the last 90 days. $0.010 per GB
👨🏻💻 Cost Tip Partition your tables whenever is possible. Image this scenario you have a 10 Terabytes DataWarehouse and only use your last month’s data. If all your tables are not partitioned this could mean $200 monthly or for a partitioned slightly more than $100 (without counting the compute cost savings!).
Since the BigQuery partition limit for each table is 4000 an interesting approach could be to set a ‘maximum history availability’ in this case could be 3 years and the older data migrate to a cheaper storage li GCS nearline ($0.004 per GB), so with this, your DataWarehouse will not grow exponentially.
2. Compute
BigQuery has two pricing models and one hybrid model:
- on-demand: pay for the number of bytes processed $5 per TB.
- flat-rate: you purchase a monthly Slot commitment (minimum commitment is 500 slots, $10 000 monthly), this means you’ll have a maximum compute capacity (500 CPUs) for your GCP Project, the advantage here is you pay a fixed amount doesn’t matter the number of TB processed.
- flat-slot: is similar to flat-rate the main difference is that the commitment is as little as 60 seconds. The cost here is $20 per hour.
👨🏻💻 Cost Tip
To decide which strategy is the best for your team you need to follow your expenses and slot utilization. Let’s check a real case and identify which pricing model is the best and why.
Cloud Monitoring
Activate this important tool.
The first time It needs to create the workstation
Then select the BigQuery dashboard
Select BigQuery Dashboard
Now Let’s focus on the ‘Slot utilization’ chart. Here we observe a few peaks over 500 that could be caused by intense not optimized queries. This could tell me that an on-demand model or flat-rate could work, to define let’s check bytes processed.

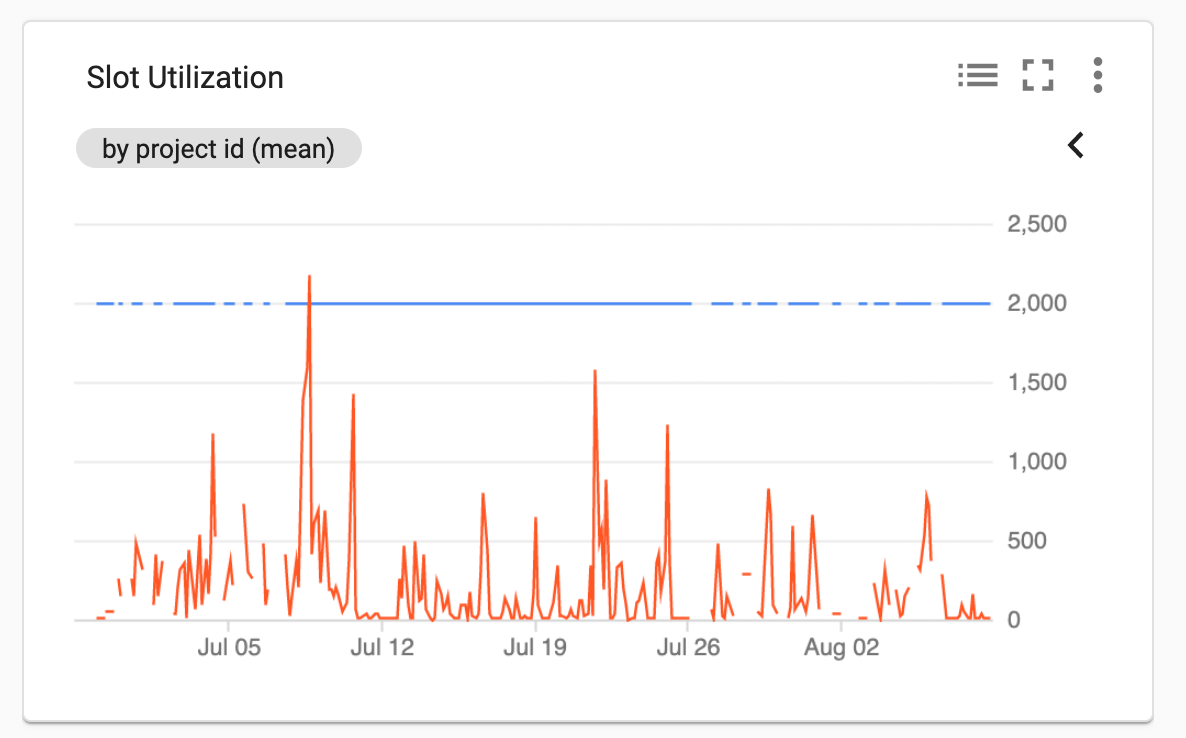
Second check the bytes processed and the daily and monthly cost. This query results in the last 30 days we processed 115 Terabytes with a total cost of $572 this means that we are far from the $10,000 fix-rate and we keep with the on-demand price model. Another insight is that on July 16 was the highest peak in terabytes processed so only on this day a good idea would have been to use flex-slot.




Performance recommendations
The best partition field (Not is always day!)
Each time I need to figure out which is the best partition strategy, I rely on the Google Cloud recommendation. At least each partition should be 1GB. This brings me that the majority of my tables are now partitioned by month.
👨🏻💻 Performance Tip
Evaluate to activate the ‘require_partition_filter’ so each time a person needs to query a table It will be required to add a Where clause filtering with the partition field.
ALTER TABLE mydataset.mypartitionedtable
SET OPTIONS (require_partition_filter=true)</span>
The best clustering strategy
Clustering is another great tool for optimizing your cost and performance. I always think clustering like a ‘box inside a box’ so to access an internal box I need to interact with the upper box.
👨🏻💻 Performance Tip
To understand this idea let’s compare the following three queries. The last one only retrieves the data within the partition, and giving the two levels of partitioning means that the query wouldn’t need to ‘open’ each box until finding the ‘city box’. All this will be reflected in a short execute time and fewer bytes consumed.
Avoid windows functions
Operations that need to see all the data in the resulting table at once have to operate on a single node. Un-partitioned window functions like RANK() OVER() or ROW_NUMBER() OVER() will operate on a single node. [Looker question]. This means that it doesn’t matter that you have the best price model with thousands of slots, still, all the data will go to a single node if you use a window function.
👨🏻💻 “Resources exceeded during query execution” Tip
There are a few strategies you could use here. First for example if you need to use OVER()you need to PARTITION the window function by date and build a string as the primary key [Looker question].
CONCAT(CAST(ROW_NUMBER() OVER(PARTITION BY event_date) AS STRING), ‘|’,(CAST(event_date AS STRING)) as **id**</span>
If your query contains an ORDER BY clause It may cause the “Resources exceeded” message, for the same reason, all the data is passed to one node. In this situation, avoid ORDER BY if your result is just for creating a new table.
Exists some strategies to increase the resources during the execution time. Please refer to the Google Cloud documentation for more details
Conclusions
BigQuery is a fantastic Data Warehouse with a challenging price model. To keep your cost-controlled without losing the performance, I recommend you to keep reading more articles and useful information I’m sure exists many excellent tips out there 👨🏻💻 👩🏻💻.
PS This month Google Cloud introduced BigQuery Omni,
It’s a flexible, multi-cloud analytics solution that lets you cost-effectively access and securely analyze data across Google Cloud, Amazon Web Services (AWS), and Azure.
I hope to be writing about my experience in the following weeks! Also, keep an eye on Materialized Views, now is in Beta that is why I didn’t add too much information here, however, I recommend you to give it a try.
PS 2 if you have any questions, or would like something clarified, ping me on Twitter or LinkedIn I like having a data conversation 😊 If you want to know about Apache Arrow and Apache Spark I have an article A gentle introduction to Apache Arrow with Apache Spark and Pandaswith some examples.
Useful links
Thanks to all these persons behind each link.
- https://cloud.google.com/blog/products/data-analytics/monitoring-resource-usage-in-a-cloud-data-warehouse
- https://cloud.google.com/bigquery/docs/reservations-workload-management#choosing_between_on-demand_and_flat-rate_billing_models
- https://github.com/GoogleCloudPlatform/professional-services/tree/master/tools/bq-visualizer
- https://cloud.google.com/bigquery/pricing#on_demand_pricing
- https://cloud.google.com/bigquery/docs/clustered-tables
- https://cloud.google.com/bigquery/docs/partitioned-tables
- https://cloud.google.com/bigquery/pricing#active_storage
- https://cloud.google.com/bigquery/pricing#flat_rate_pricing
- https://cloud.google.com/bigquery/docs/estimate-costs
- https://cloud.google.com/storage/pricing
- https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language
- https://medium.com/enkel-digital/googles-big-query-resources-exceeded-during-query-execution-%EF%B8%8F-13c20b6693e2
- https://discourse.looker.com/t/resources-exceeded-during-query-execution-when-building-derived-table-in-bigquery/4414
- https://cloud.google.com/bigquery/docs/writing-results#large-results